
























Wallis Sean
Γλώσσα
Αγγλική
Ημερομηνία
28/06/2013
Διάρκεια
37:21
Εκδήλωση
Ημερίδα για τη δημιουργία και ανάλυση των διαχρονικών σωμάτων κειμένων
Χώρος
Κεντρικό κτίριο Πανεπιστημίου Αθηνών
Διοργάνωση
Τομέας Γλωσσολογίας - Τμήμα Φιλολογίας - Εθνικό και Καποδιστριακό Πανεπιστήμιο Αθηνών
Κατηγορία
Γλωσσολογία / Γλωσσικά Θέματα
Ετικέτες
διαχρονικά σώματα κειμένων, σώματα κειμένων του Λονδίνου
Τα ερευνητικά προγράμματα «σωμάτων κειμένων του Λονδίνου»: Μαθήματα για το σχεδιασμό διαχρονικών σωμάτων κειμένων
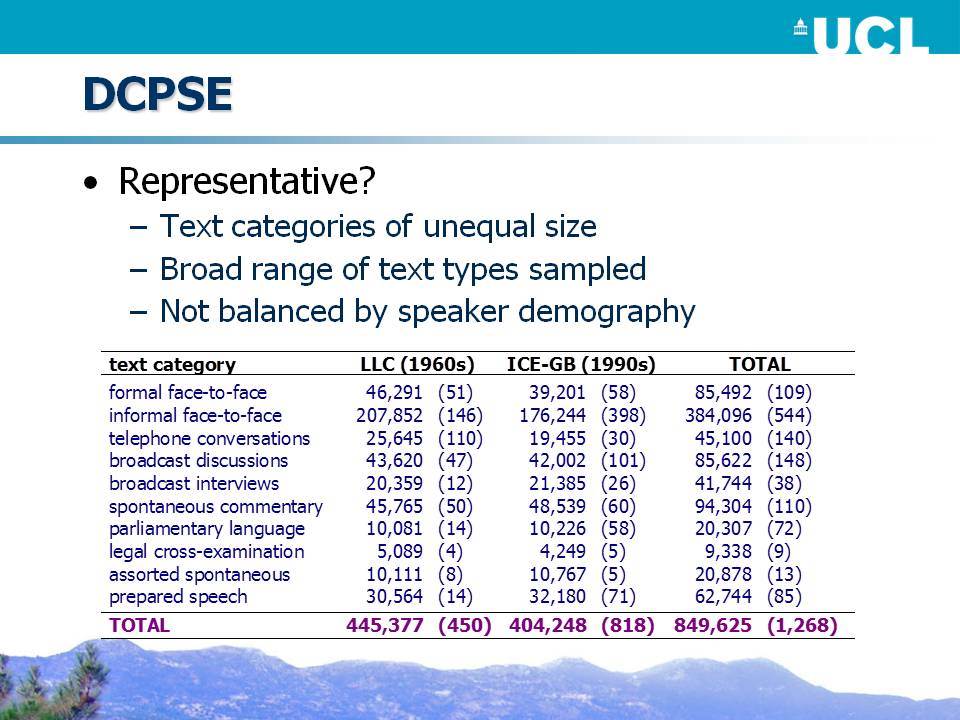
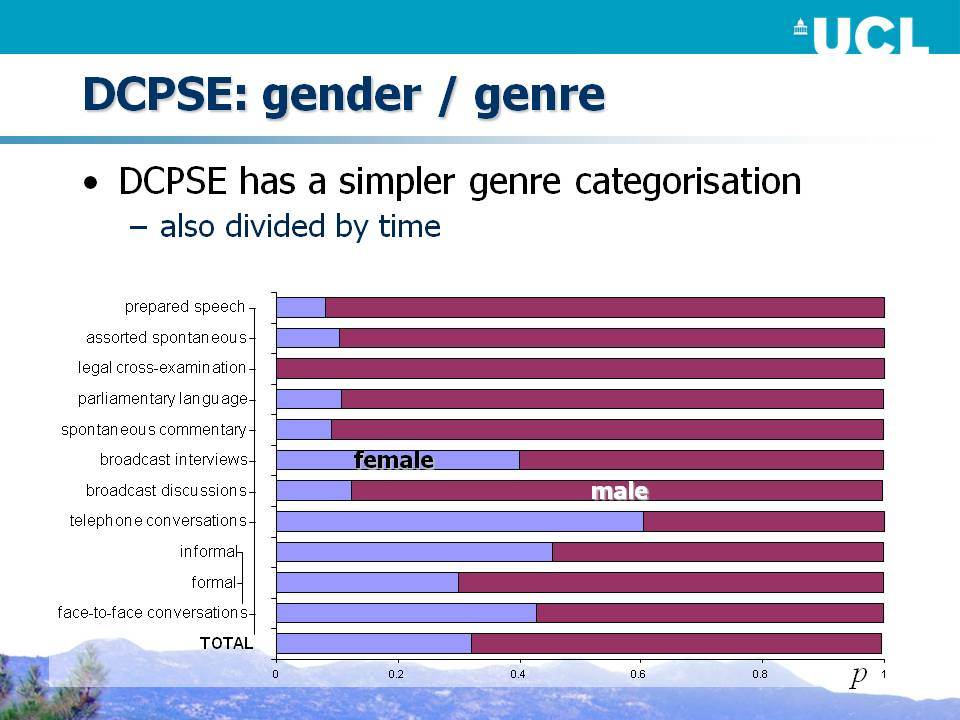
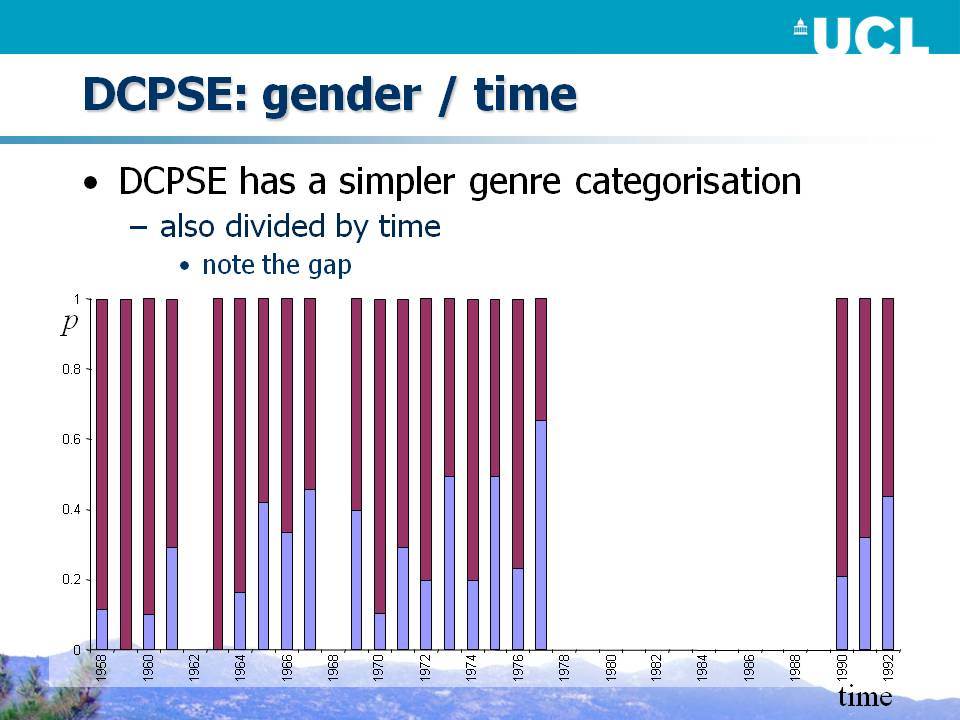
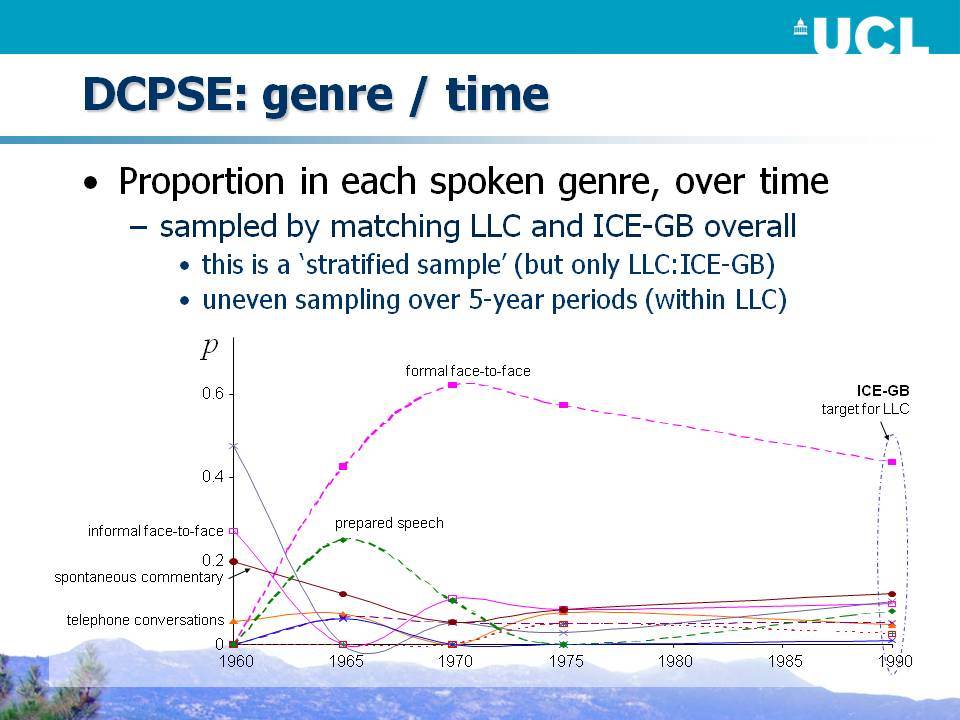
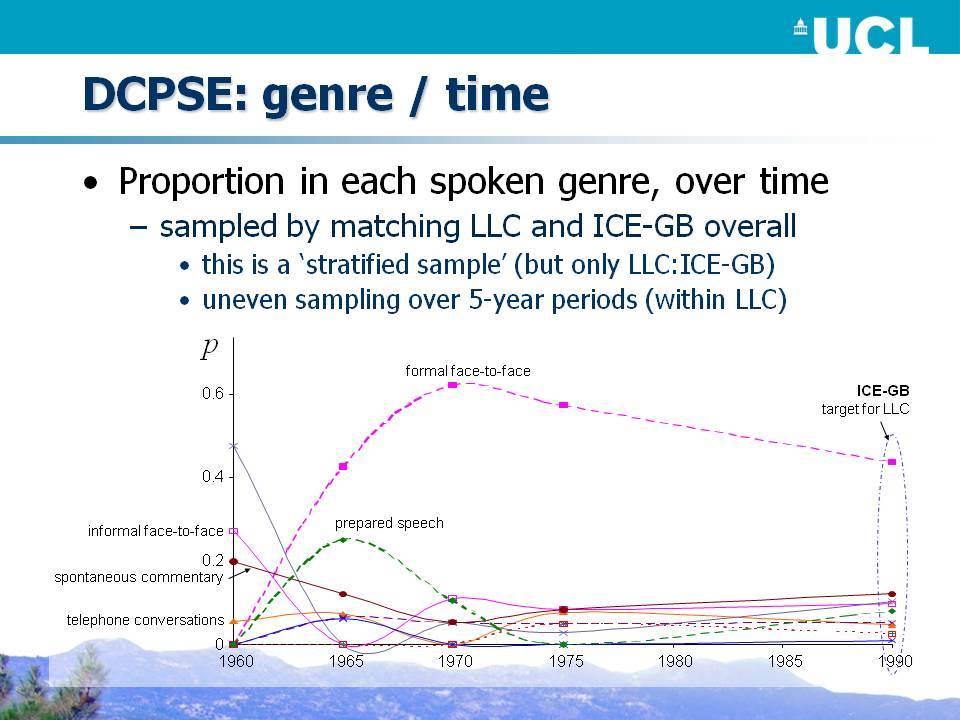
Το Βρετανικό Τμήμα του Διεθνούς Σώματος Κειμένων της Αγγλικής (ICE-GB) αποτελεί ένα μικρό αλλά σκόπιμα ευρύ σώμα κειμένων, τουλάχιστον με όρους εύρους των κειμενικών ειδών που περιλαμβάνονται. Είναι αξιοσημείωτο ότι το 60% του σώματος κειμένων αποτελείται από ορθογραφικά μεταγραμμένα προφορικά κείμενα και, λαμβάνοντας υπόψη κάποιο πιθανό προσχεδιασμό, γύρω στο 45% είναι αυθόρμητο. Το Διαχρονικό Σώμα Προφορικών Κειμένων της Σημερινής Αγγλικής (DCPSE) περιλαμβάνει δειγματοληπτικά 2/3 του προφορικού τμήματος του ICE-GB, το οποίο συνδυάζεται με παρόμοια ποσότητα κειμένων που προέρχονται από ένα παλαιότερο σώμα κειμένων, το προφορικό μέρος του London-Lund Corpus (LLC), που επίσης δημιουργήθηκε στο Survey of English Usage. Τα σώματα κειμένων DCPSE και ICE-GB επισημειώθηκαν για γραμματικές κατηγορίες και συντακτικά συστατικά με μια γραμματική που βασίζεται στο Quirk et al. (1985), η οποία επιτρέπει ένα ευρύ φάσμα ερευνητικών ερωτήσεων σχετικά με τη γραμματική.
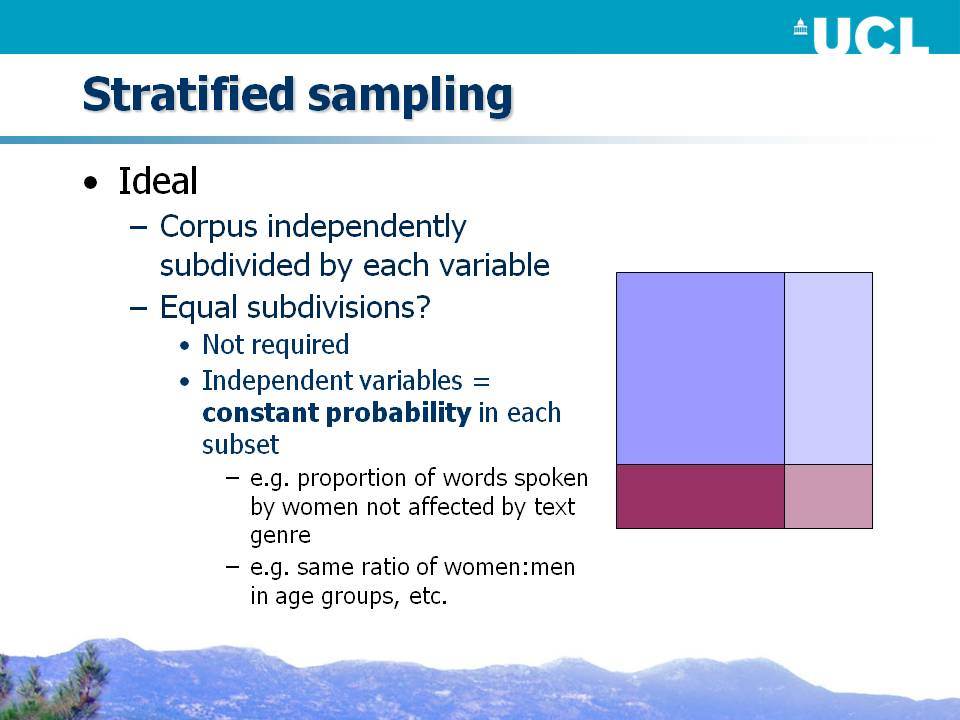
Στην ημερίδα επιχειρούμε μια κριτική επισκόπηση του σχεδιασμού αυτών των «σωμάτων κειμένων του Λονδίνου» (ICE-GB, LLC και DCPSE) σε σχέση με τις αρχές πειραματικής δειγματοληψίας και σχεδιασμού και εξάγουμε τα μαθήματα για το σχεδιασμό διαχρονικών σωμάτων κειμένων:
- Τι εννοούμε με τη φράση «ισορροπημένο σώμα κειμένων»;
- Πώς επηρεάζουν οι αποφάσεις δειγματοληψίας που παίρνουν οι δημιουργοί των σωμάτων κειμένων το είδος των ερευνητικών ερωτημάτων που μπορούν να τεθούν σήμερα στα δεδομένα;
- Θα πρέπει τα δεδομένα να είναι πιο κοινωνιογλωσσικά αντιπροσωπευτικά με όρους κοινωνικών τάξεων και περιοχής;
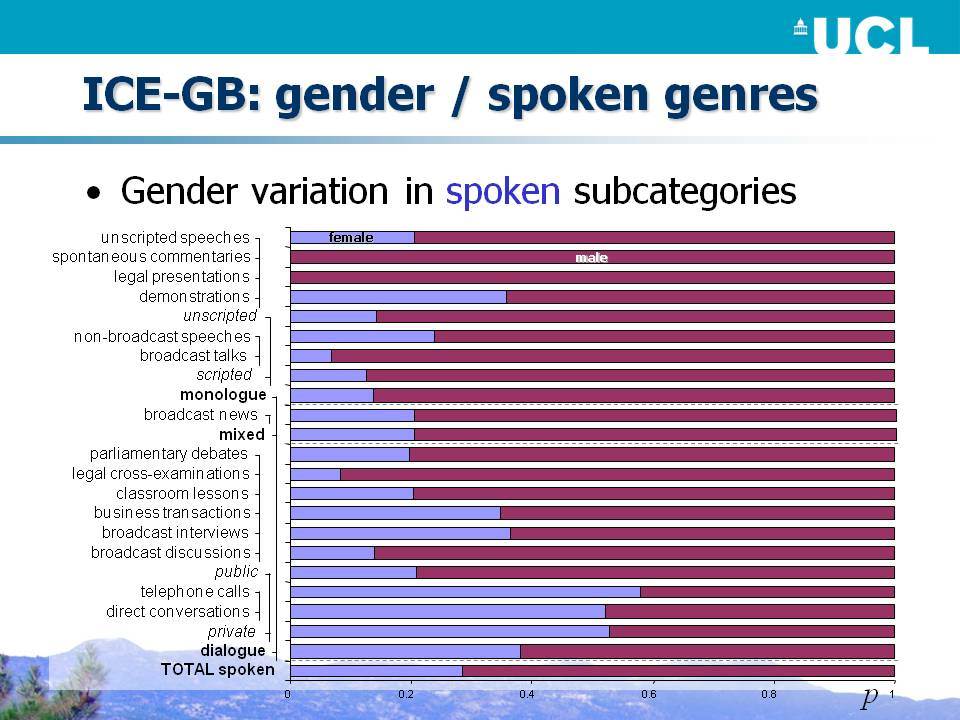
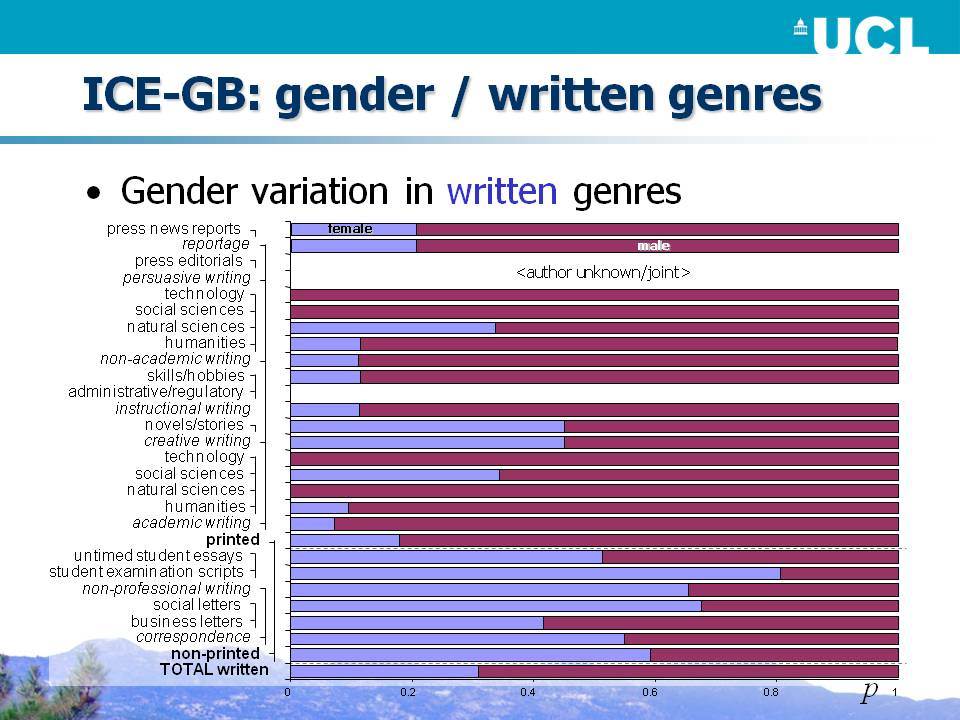
- Λήφθηκαν τα κείμενα δειγματοληπτικά με τρόπο ώστε ομιλητές όλων των κατηγοριών φύλου και ηλικίας να αντιπροσωπεύονται σε κάθε κειμενικό είδος; Κάτι τέτοιο αποτελεί μια καλή σχεδιαστική αρχή;
Η ανακοίνωση πραγματοποιήθηκε στο πλαίσιο ημερίδας που διοργανώθηκε από το πρόγραμμα «Διαχρονικό Σώμα Ελληνικών Κειμένων του 20ού αιώνα» (Greek Corpus 20, http://greekcorpus20.phil.uoa.gr/), το οποίο συγχρηματοδοτείται από το Ευρωπαϊκό Κοινωνικό Ταμείο και την Ελλάδα (Ερευνητικό πρόγραμμα «Αριστεία»). Στόχος της ημερίδας ήταν η συζήτηση και ο προβληματισμός για τις βασικές αρχές και τις ορθές πρακτικές που αφορούν στη συγκρότηση διαχρονικών σωμάτων κειμένων με σκοπό τη γλωσσολογική έρευνα. Η εμπειρία μελετητών που έχουν εργαστεί σε σχετικά ερευνητικά προγράμματα σε άλλες γλώσσες αναμένεται να συμβάλει σημαντικά στη διαμόρφωση των στόχων και των πρακτικών του διαχρονικού σώματος κειμένων της Ελληνικής, καθώς, σε αντίθεση με άλλες γλώσσες, η Ελληνική δεν έχει επωφεληθεί έως τώρα από την ανάπτυξη της υπολογιστικής γλωσσολογίας σωμάτων κειμένων στο βαθμό που θα αναμενόταν: η έλλειψη ενός διαχρονικού σώματος κειμένων της Ελληνικής αποτελεί ένα μείζον κενό στην ελληνική γλωσσολογία και το ερευνητικό πρόγραμμα στοχεύει να καλύψει αυτό το κενό, αναπτύσσοντας ένα σώμα κειμένων 20 εκατ. λέξεων για τις πρώτες εννέα δεκαετίες του 20ου αιώνα, το οποίο θα ενσωματωθεί στο προϋπάρχον σώμα κειμένων 30εκατ. λέξεων του ΣΕΚ. Στόχος του σώματος κειμένων είναι η μελέτη περιοχών πρόσφατης γλωσσικής αλλαγής (τόσο σε γραμματικό όσο και σε λεξιλογικό επίπεδο) μέσω της ανάλυσης αυθεντικών κειμένων.
Ο Sean Wallis είναι ερευνητής στο Survey of English Usage του Πανεπιστημίου του Λονδίνου. Συμμετείχε ως ερευνητής στην Ομάδα Τεχνητής Νοημοσύνης του Πανεπιστημίου του Nottingham (1989-1995) και μετέπειτα εργάστηκε στο University College London. Έχει αναλάβει την εποπτεία της ολοκλήρωσης του British Component του International Corpus of English (ICE-GB) και του Diachronic Corpus of Present-Day Spoken English (DCPSE), και των δύο συντακτικά σχολιασμένων κειμένων, και δημιούργησε το λογισμικό ICECUP για την ανάλυση αυτών των δύο σωμάτων κειμένων. Έχει γράψει το βιβλίο Exploring Natural Language (2002, με τους B. Aarts και G. Nelson), καθώς και μια σειρά από άρθρα σχετικά με τη μεθοδολογία των σωμάτων κειμένων, το σχεδιασμό και την επισημείωσή τους, τις μεθόδους επισημείωσης και αναζήτησης και τον πειραματικό σχεδιασμό και ανάλυση. Έχει επίσης αναπτύξει υπολογιστικούς αλγορίθμους και προσεγγίσεις στην υπολογιστική γλωσσολογία σωμάτων κειμένων και στο ιστολόγιό του corp.ling.stats αναπτύσσει ζητήματα σχετικά με τον πειραματικό σχεδιασμό και τη στατιστική για τη γλωσσολογία των σωμάτων κειμένων. Πρόσφατα επιμελήθηκε τον τόμο The Verb Phrase in English (2013, με τους B. Aarts, J. Close και G. Leech) και δημιούργησε μια εφαρμογή για κινητά τηλέφωνα της γραμματικής The Interactive Grammar of English (2011, με τον B. Aarts).



: Issues of design and compilation")