
































Yangarber Roman
Γλώσσα
Αγγλική
Ημερομηνία
13/09/2011
Διάρκεια
52:19
Εκδήλωση
European Intelligence and Security Informatics Conference (EISIC) 2011
Χώρος
Titania Hotel
Διοργάνωση
Hellenic American University
University of Southern Denmark
University of Arizona
Springer Wien New York
Κατηγορία
Πληροφορική
Ετικέτες
υπολογιστική γλωσσολογία, on-line ροή ειδήσεων
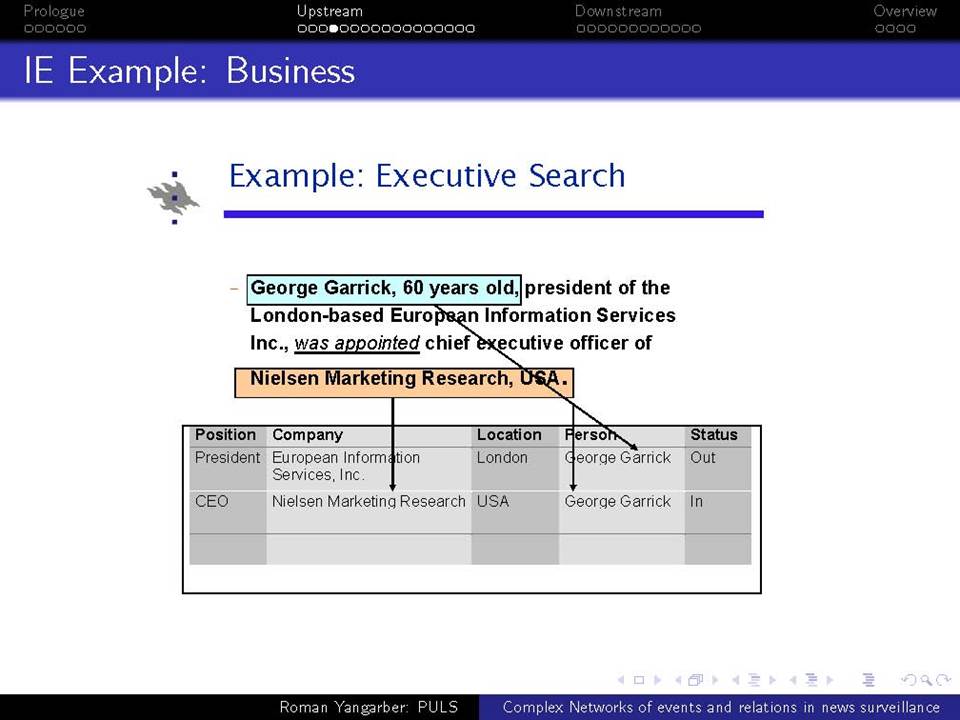
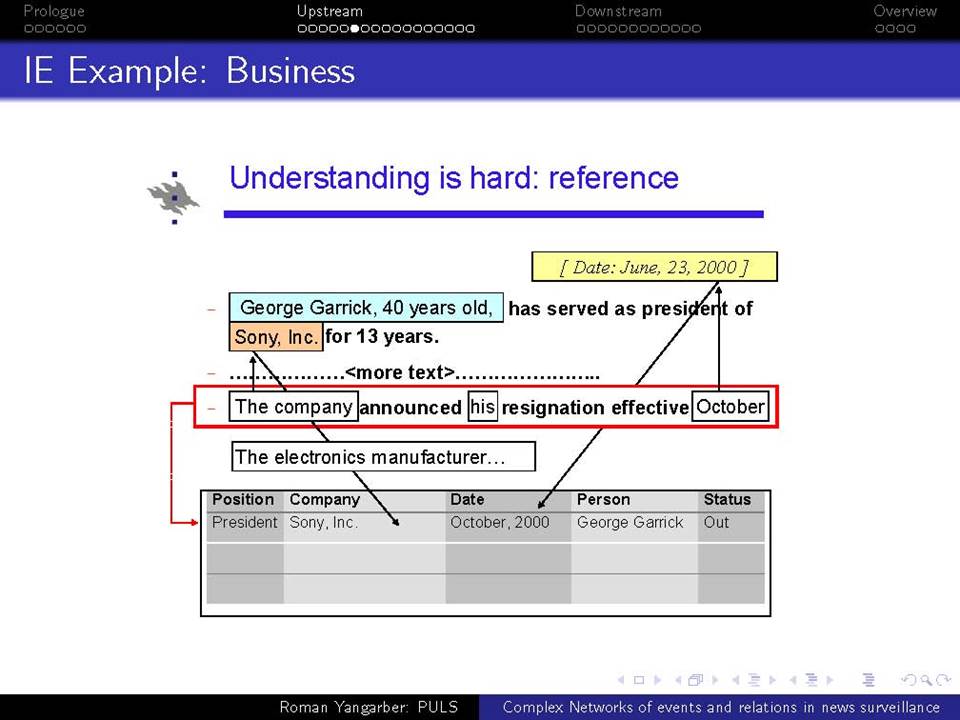
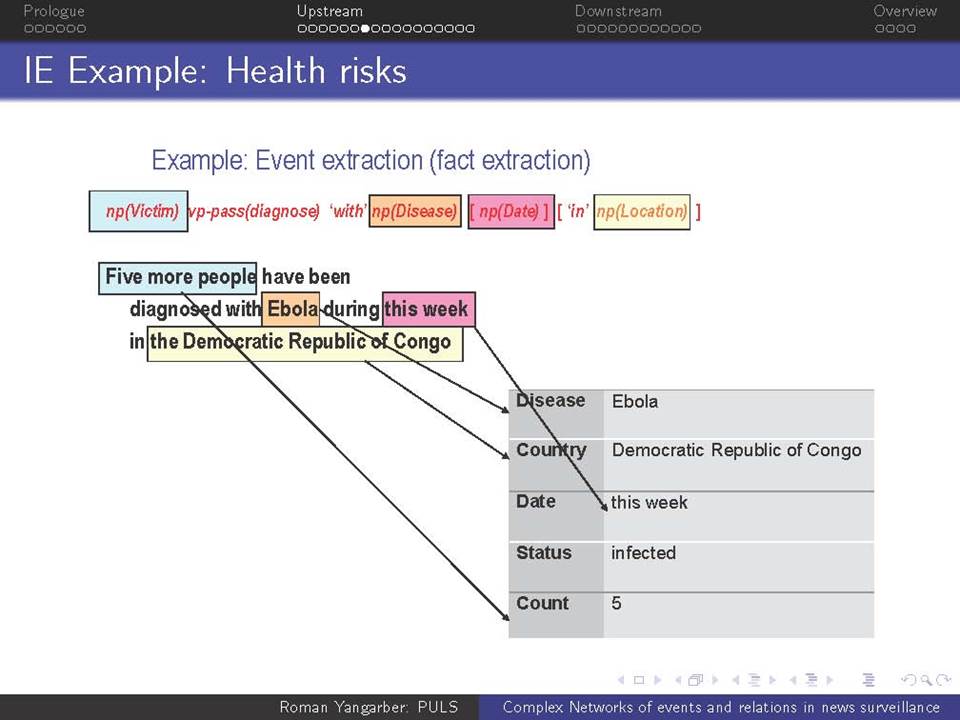
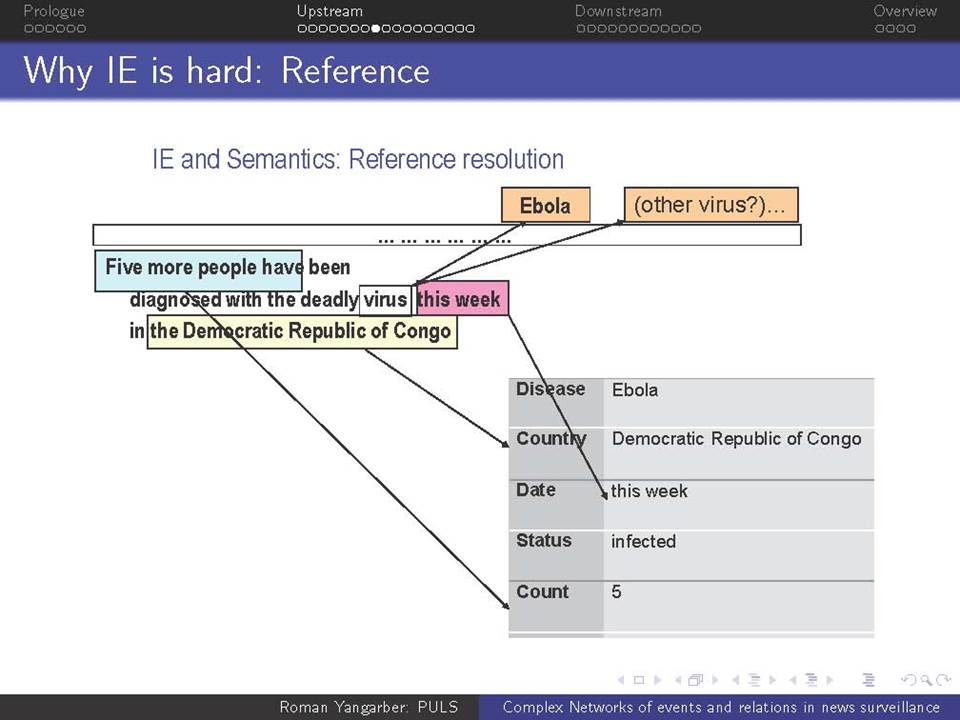
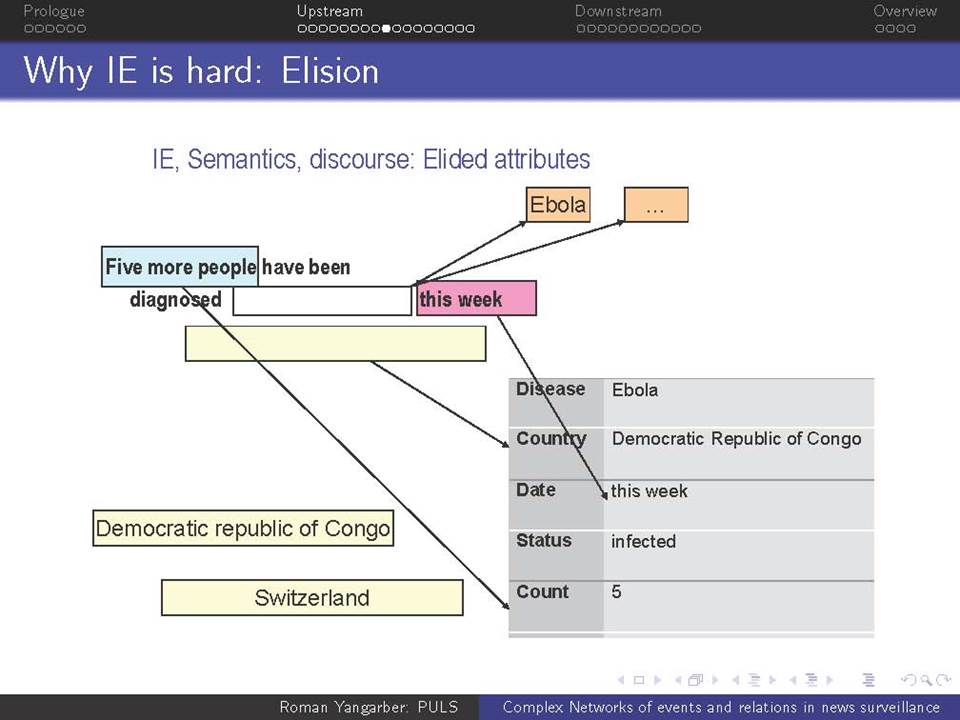
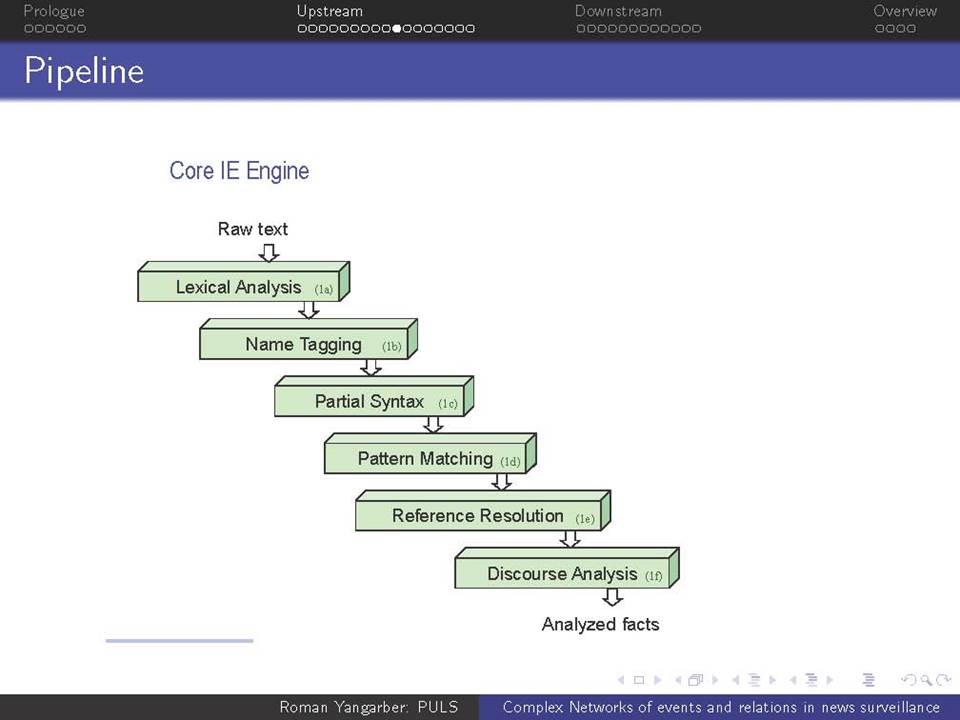
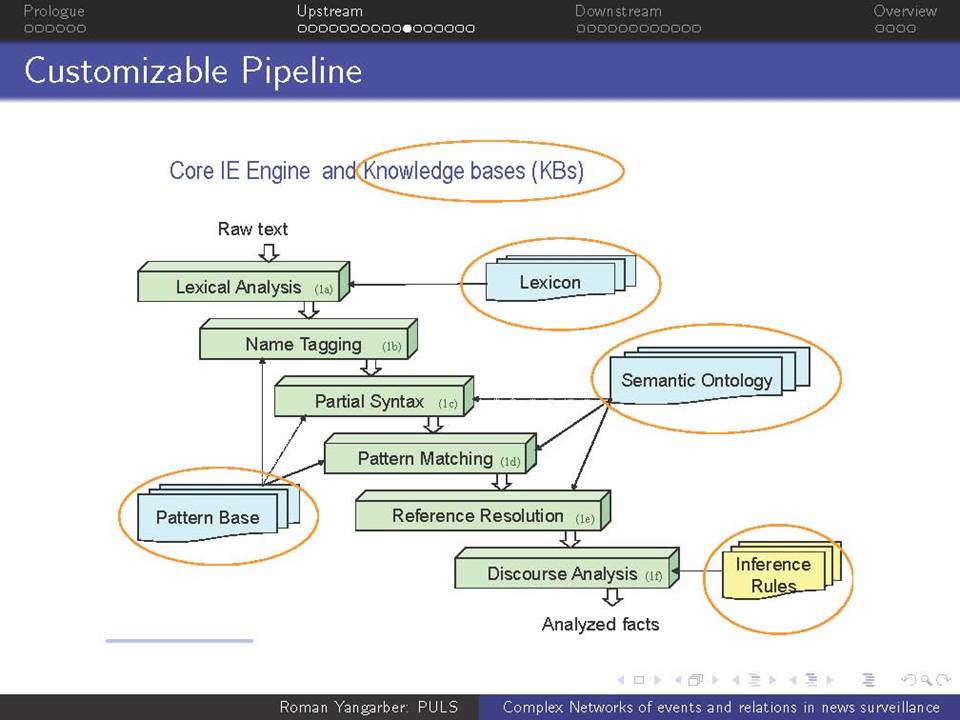
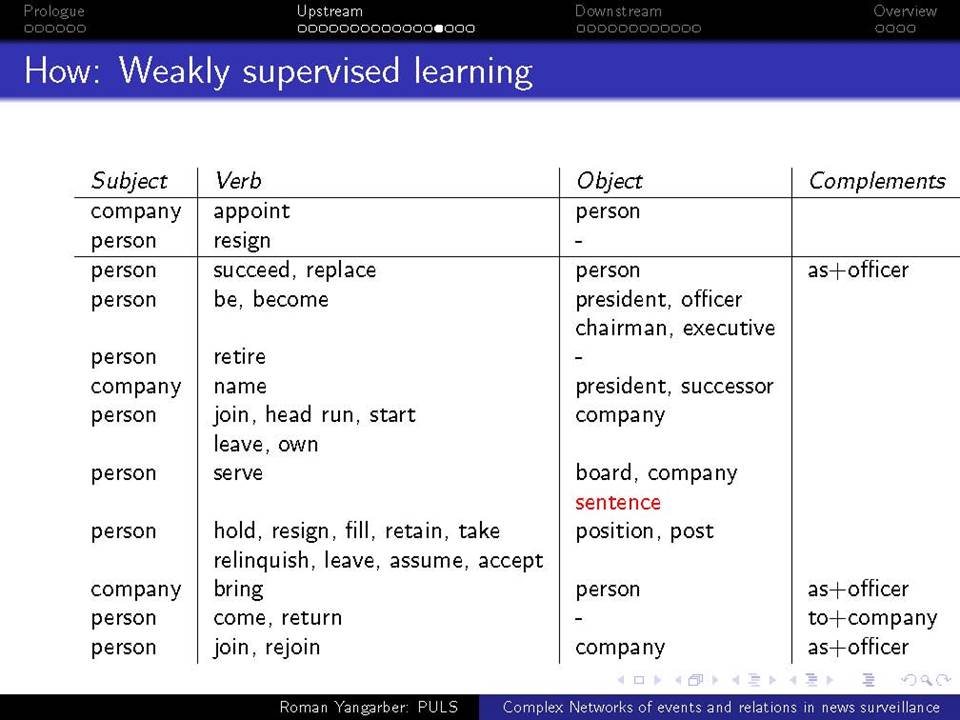
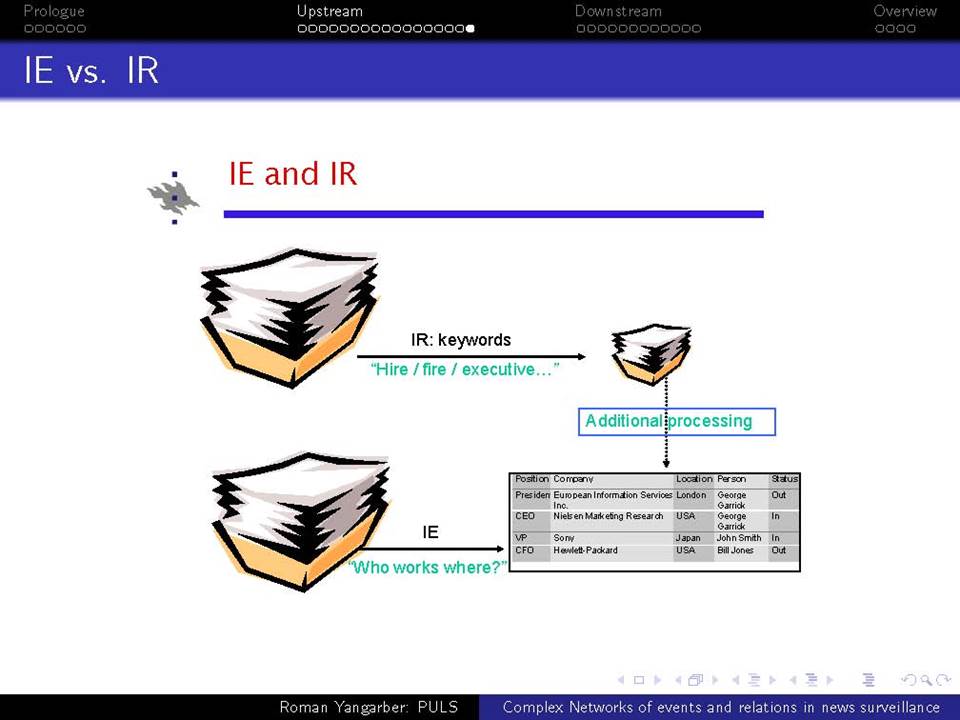
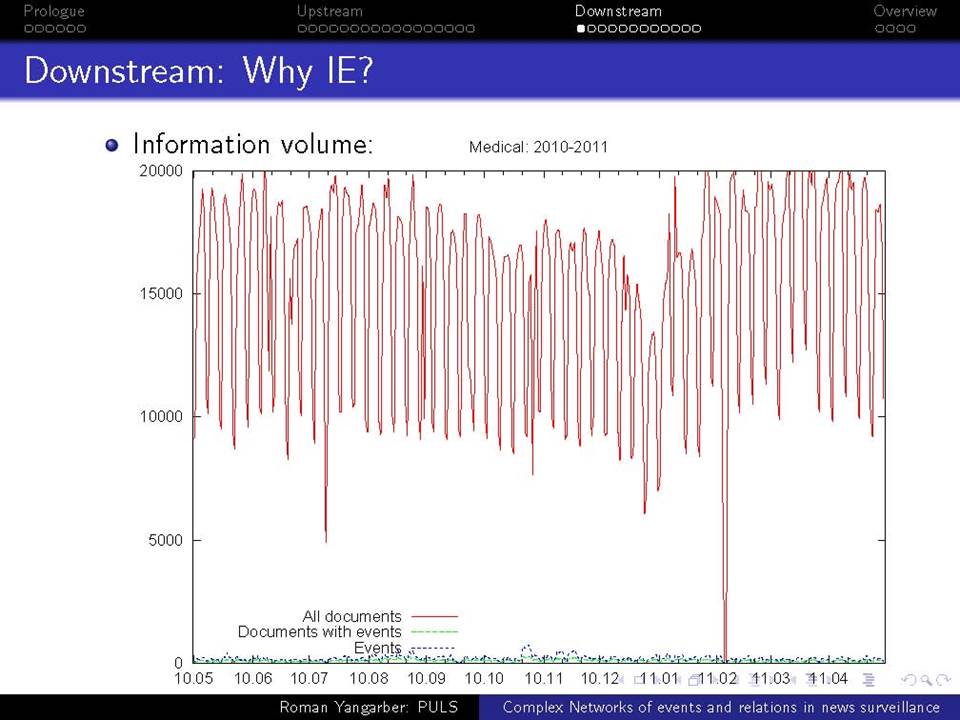
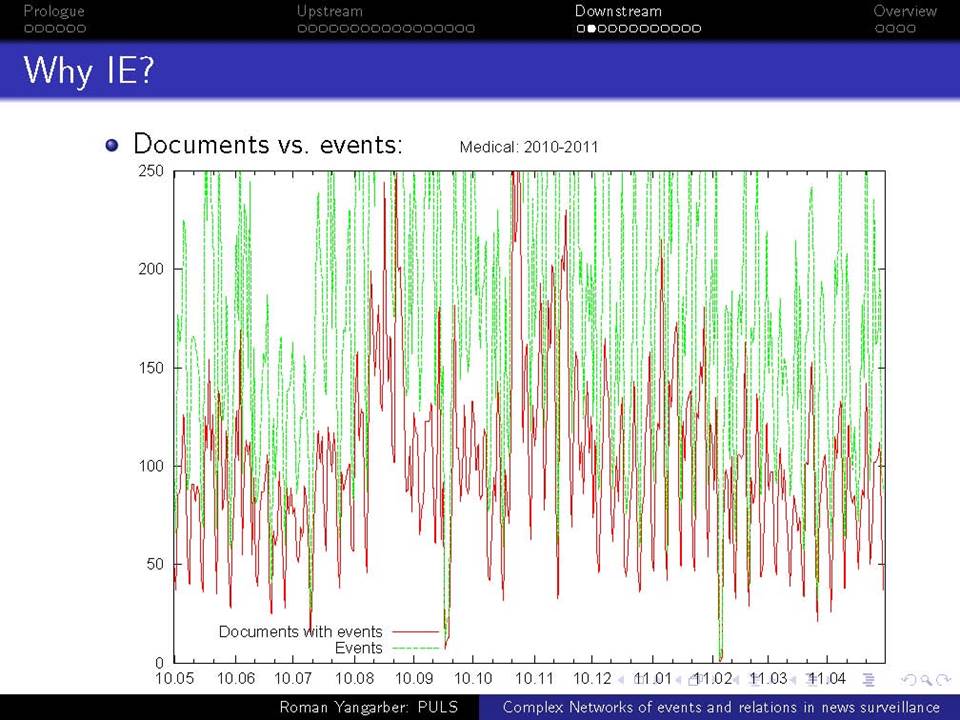
Όταν βρισκόμαστε αντιμέτωποι με την ανάγκη να αναλύσουμε τεράστιες ποσότητες κειμένων-δεδομένων που βρίσκονται στο διαδίκτυο, χρειαζόμαστε μεθόδους που ξεπερνούν τις αναζητήσεις με βάση λέξεις-κλειδιά. Η ευρείας κλίμακας επιτήρηση της on-line ροής ειδήσεων απαιτεί την κατανόηση του κειμένου σε ένα βαθύτερο επίπεδο από αυτό που παρέχεται μόνο από τα ονόματα και τις λέξεις-κλειδιά, και γίνεται απαραίτητη για την κατανόηση πολύπλοκων αλληλεπιδράσεων μεταξύ των προσώπων, των γεγονότων και των συσχετισμών τους. Συζητείται εδώ η αλληλεπίδραση δύο πτυχών αυτού του είδους της βαθύτερης ανάλυσης.
α) πώς να εξαχθεί γνώση από τη συνεχόμενη ροή κειμένου και β) πώς αυτή η γνώση μπορεί να χρησιμοποιηθεί σε μεταγενέστερες εφαρμογές
Χρησιμοποιούνται ως ζωντανά παραδείγματα πολλά συστήματα σε διαφορετικά πεδία εφαρμογής: εγκληματικότητα και ασφάλεια, επιτήρηση επιδημιών και ασφάλεια επιχειρήσεων. Παρουσιάζονται οι εμπειρίες από την ανάπτυξη των συστημάτων αυτών και από την αλληλεπίδραση με πραγματικούς χρήστες, ειδικούς στους αντίστοιχους τομείς.
Ο Roman Yangarber έλαβε το μεταπτυχιακό και διδακτορικό του στο Πανεπιστήμιο της Νέας Υόρκης (NYU), στην Πληροφορική με ειδίκευση στην Επεξεργασία Φυσικής Γλώσσας. Πριν να μετακομίσει στο Ελσίνκι της Φιλανδίας το 2004, ήταν Επίκουρος Καθηγητής στο Ινστιτούτο Μαθηματικών Επιστημών Courant, ΝΥU, όπου είχε ειδικευτεί στη υπολογιστική γλωσσολογία, εστιάζοντας σε αλγόριθμους μηχανικής μάθησης για την απόκτηση σημασιολογικής γνώσης από απλό κείμενο. Ειδικότερα, το ενδιαφέρον εστιάζεται στην απόκτηση γνώσης από μεγάλη ροή ειδήσεων. Ο Roman Yangarber υπήρξε ο διοργανωτής, μέλος της συντακτικής επιτροπής και μέλος της επιτροπής προγράμματος σε πολλές επιστημονικές εκδηλώσεις, συνέδρια, οργανώσεις και περιοδικά και έχει υπηρετήσει σε επιτροπές αξιολόγησης για το Αμερικανικό Εθνικό Ίδρυμα Επιστημών (US National Science Foundation). Έχει πάνω από 60 δημοσιεύσεις σε διεθνή συνέδρια, περιοδικά και κεφάλαια βιβλίων. Από τότε που πήγε στο Τμήμα Πληροφορικής, Πανεπιστήμιο του Ελσίνκι, κατέχει τη θέση του Καθηγητή και σήμερα διευθύνει δύο εθνικά ερευνητικά έργα, ενώ συμμετέχει και σε δύο άλλα (ΕΕ και εθνική χρηματοδότηση), στα οποία εποπτεύει μεταπτυχιακούς και διδακτορικούς φοιτητές στον τομέα της εξόρυξης κειμένου και της υπολογιστικής γλωσσολογίας. Τέλος, είναι επιστημονικός υπεύθυνος του έργου PULS: ανάλυση κειμένου για την επιτήρηση των μέσων μαζικής ενημέρωσης.
2. M. Atkinson, J. Piskorski, E. van der Goot, R. Yangarber. Multilingual real-time event extraction for border security intelligence gathering. Counterterrorism and open-source intelligence (Lecture notes in social networks, Vol. 2. U.-K. Wiil, editor). Springer.
3. P. von Etter, S. Huttunen, A. Vihavainen, M. Vuorinen, R.
Yangarber. Assessment of utility in Web mining for the domain of public health. In Proceedings of LOUHI-2010: the second Louhi workshop on text and data mining of health documents, at the NAACL/HLT Conference, (2010) Los Angeles, California
4. J. Piskorski, M. Atkinson, J. Belyaeva, V. Zavarella, S. Huttunen, R. Yangarber. Real-time text mining in multilingual news for the Creation of a Pre-frontier Intelligence Picture. In Proceedings of ISI-KDD: ACM SIGKDD Workshop on intelligence and security informatics, at KDD-2010: 16th Conference on
knowledge discovery and data mining (2010) Washington, DC
